



Misadventures turning on Workload Management with vSphere 7
For most folks that have been involved with SDDC for some time, this is going to be a lot of basic and obvious. As a quick disclaimer, I’ve to add that when i started down this path back in April, 2020(which was around the time vSphere 7.0 was released), I was (and still am) pretty new to the world of Home Lab and SDDC. As someone who has primarily worked on the application/software layer, I have been oblivious to the underlying infrastructure that made it all possible. I wanted to be educated and to learn more about the underpinnings of how Compute, Storage, Network come together to enable and drive modern innovations.
I was just getting into the Kubernetes space through the VMware Event Broker Appliance Fling and was super excited about the whole Cloud Native movement! While there are a lot of easy (😬 thanks to the Cloud Providers, Cluster API, Kind, minikube) or simpler alternatives to get a Kubernetes cluster going, I wanted to go down the vSphere 7 rabbit hole primarily to understand VMware’s SDDC stack and its capabilities. So let’s checkout my journey…
Lab BOM
Here is my BOM when I started this Journey to turn on the Workload Management in vSphere 7.0 - I spent a lot on Compute and minimally on storage and networking equipments.
Hosts
- 2x Dell R620 (unsupported CPU for vSphere 7.0)
- CPU: 2x E5-2630 v2
- Memory: 128GB RAM
- Storage:
- Model: PERC H310 Mini (for monolithic)
- 2x 500GB HDD
- 2x Dell R730
- CPU: 2x E5-2620 v3
- Memory: 128GB RAM
- Storage:
- Model: PERC H730 Mini
- 2x 500GB HDD
- 2x 100GB SSD
SDDC Setup
- vCenter 7.0 GA
- Mgmt: ESXi 6.7 on 2x R620
- Compute: ESXi 7.0 GA on 2x R730
- 2 node vSAN Cluster enabled (after purchasing a couple of 100GB SSDs)
Networking
- TP-Link (an old leftover router)
- routes to my ISP through a firewall
- Cisco 2960 Switch (mainly for VLANs)
- 10.10.10.0/24 - (VLAN 10) Management
- 10.10.20.0/24 - (VLAN 20) VM
- 10.10.30.0/24 - (VLAN 30) vMotion
- 10.10.50.0/24 - (VLAN 50) vSAN
- 10.10.60.0/24 - (VLAN 60) NSX Overlay/TEP
- 10.10.70.0/24 - (VLAN 70) NSX Uplink
- default route back to TP-Link
As pre-requisites, Kubernetes on vSphere demanded a lot!
- vSphere cluster with at least 3 ESXi hosts. If you are using vSAN you need a minimum of 4 ESXi hosts
- Configure the vSphere cluster with high-availability (HA) enabled
- Configure the vSphere cluster with the Distributed Resource Scheduler (DRS) enabled - DRS automation must be set to Fully Automated mode
- The vSphere cluster must use shared storage such as vSAN. Shared storage is required for vSphere HA, DRS, and for storing persistent container volumes
- Deploy NSX-T for container networking
So right away, for someone that is new to managing a SDDC (even in a homelab capacity), Workload Management was difficult to enable. However, I saw this as an opportunity to dive headfirst into SDDC and have a foundation with vSphere, vSAN and NSX stood-up to have an Enterprise-like foundation where i can then build my other capabilities for EUC. So it has to be a win-win situation, right?
and.. 9 months later…
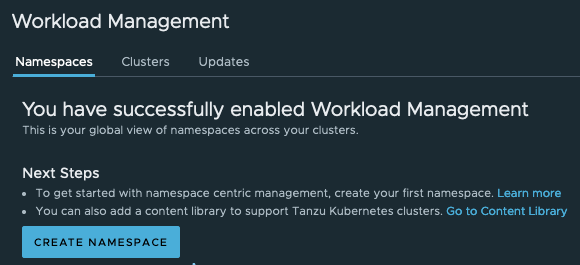
There has been a ton of learnings from misconfigurations and unknowns along the way which I’m going to document in this blog in the hopes that it benefits anyone else that is new to this space!
Challenge 1: A Shared Storage
The first challenge that I tried to solve was having a shared Storage for the lab. I looked at either turning on vSAN or setting up NFS on a new server
Setting up vSAN
From acquiring my hardware to getting my homelab primed for vSAN, it took me some time to work my way up to enabling vSAN (major accomplishment in my mind). Since I needed Flash based cache drives I ended up buying 4x 100GB SSD drives for cache that would let me enable a 2 node vSAN. This was supposed to be fairly easy but I had challenges with vSAN nodes and the witness modes getting partitioned. It was due to the flat network I had at the time and was able to resolve it by enabling the witness node traffic on the management network.
Referenced Links
- https://www.virtuallyghetto.com/2018/04/native-mac-learning-in-vsphere-6-7-removes-the-need-for-promiscuous-mode-for-nested-esxi.html
- https://kb.vmware.com/s/article/2150433?lang=en_US
- https://docs.vmware.com/en/VMware-vSphere/6.7/com.vmware.vsphere.vsan-planning.doc/GUID-03204C22-C069-4A18-AD96-26E1E1155D21.html
I eventually ended up buying a Cisco 2960 Switch where I was able to setup some VLANs and get the traffic isolated properly.
Setting up NFS - Unraid
Even though I had the vSAN enabled, I didn’t have a lot of space that I could work with. So I promptly started to look for a proper Storage solution and ended up choosing Unraid(Thanks to the recommendation from Erick Marshall Follow) for my NFS). Needless to say I had a bunch of challenges here as well!
- While there are some SuperMicro options for NFS, I was in the mode of buying Dell Servers and ordered an old R510 server with amazing specs.Unfortunately it arrived broken and I had to return it
- I ended up getting another Dell server R720XD which didn’t have the right HBA card (Unraid requires that you expose the disks as JBOD) but had 92gb of RAM.
- Rather than buying a proper HBA card, I hacked around by setting up Raid 0 volumes with 1 drive each (going against all the advices on the forums) and enabled
write throughon each volume - I thought I was set but after running some VMs for a couple of days on Unraid, i realized that the VMs were “working” right up until the RAM limit were reached. The 92GB of RAM were being used as cache by Unraid.
- I tried not to spend a lot of money but ended up getting a backplane for my R720XD so i could add 2 SSD drives for cache. I managed to screw up by ordering SFF backplane and not the LFF backplane I had 😭 …and there went my negotiated 10$ bargain on returning the cable for the right ones
- I finally installed the cache drives (2x 1TB SSD) and also enabled LAG on the two NICs for the peak performance that I could afford
Unraid Spec: Dell R720XD
- CPU: 2x E5-2670
- Memory: 92GB RAM
- Storage:
- Model: PERC H710
- 12x 3.5" 3TB HDD
- 2x 2.5" 1TB SSD
Challenge 2: NSX
I knew this was going to be a huge hurdle since I had NO experience with NSX, Absolutely NONE! There were two uses for NSX in my lab
- I needed the setup for WCP
- I wanted to leverage NSX load balancers for my EUC setup (UAGs, UEM, Access etc.)
Attempt #1: Ubuntu File System Corruption
I was able to setup NSX minimally late last year using Keith Lee’s Follow blog and then I had to take a break from Lab for mainstream EUC work. I also had to change my priorities so I could deploy an Load Balancer for the EUC lab. For a brief moment, I went down the path of taking a whole NSX-T 3.0 Install, Configure, Manage so I can setup NSX properly. Needless to say but I lost some tempo due to competing priorities and NSX Lab took a backseat in the fall of 2020.
After the holidays when I looked at my whole setup , I figured I’d be better off if I seek some help! I got some assistance from Aaron Ramirez Follow and we first tried to upgrade NSX-T to 3.0.2 and when the upgrade didn’t work from the GUI, we decided to start over with NSX-T 😅.
This time around, I wanted to leverage my Unraid and decided to install NSX w/ Unraid as the datastore and this was a bad move on my part. I’d setup Unraid to use the cache for VMs and had also setup a mover job that would move the files from cache to the HDD overnight. My theory is that the Unraid mover job somehow corrupted the Ubuntu file system. The next day after all the setup was “complete”, I got a nice index out of sync error all over the NSX Manager UI
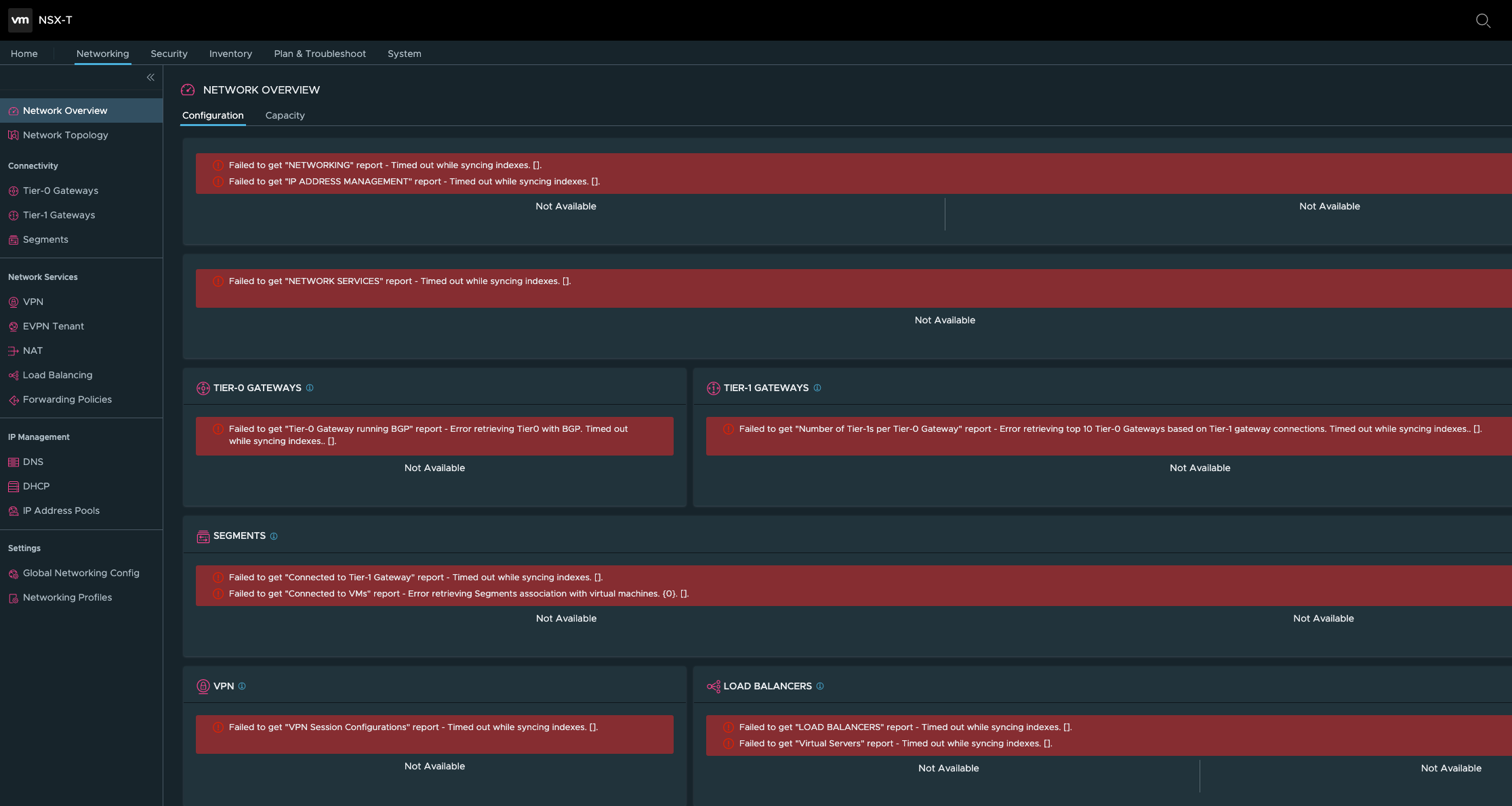
I couldn’t find anyone that seemed to have faced this issue before and decided to start over…
Referenced Links
Attempt #2: NSX Cleanup and Reinstall
I went through the reinstall and configured process for NSX, boldly deciding to stick with Unraid! I ended up having the same issues but got worse this time - a login loop upon boot of NSX Manager (without any user interaction)
Anyone seen #NSX mgr go crazy like this? this happened after a CLI reboot (which i thought would solve a "timed out while syncing indexes" error). This is a brand new deployment with no VM workloads #vexpert pic.twitter.com/5EgHSn4INV
— PK (@pkblah) January 27, 2021
I decided to start over but only because I was getting impatient and figured I’d have more luck reinstalling than having to troubleshoot the Ubuntu file system.
Referenced Links
- https://kontainers.in/2019/09/03/how-to-cleanup-an-orphaned-esxi-host-that-is-nsx-t-prepared/
- https://blog.zuthof.nl/2020/01/29/manually-removing-faulty-nsx-t-transport-nodes/
Attempt #3: Recovering a Corrupted File System
Around this time, NSX-T 3.1 had been released. I had worked with Aaron to also setup AVI load balancer and since NSX-T 3.1 had some improvements for AVI LB, we decided to setup NSX-T 3.1. By now, I got wiser and installed the manager on a local datastore and the edge on Unraid (I wasn’t going to give up on my NFS easily)
By 11 PM on a Friday night, I had gotten NSX-T fully configured to cover the pre-requisites for Workload Management. Next morning, the Unraid mover had moved the files from cache to HDD and one of the edge nodes started showing symptoms of disk corruptions. I wasn’t able to login to the edge node using my root or admin password. It seemed to have either reverted or gotten corrupted. I was able to find an article that helped recover the file system and restore the root password.
Referenced Links
Challenge 3: WCP
And finally it seemed like I’m all set to enabled Workload Management on my Compute cluster!
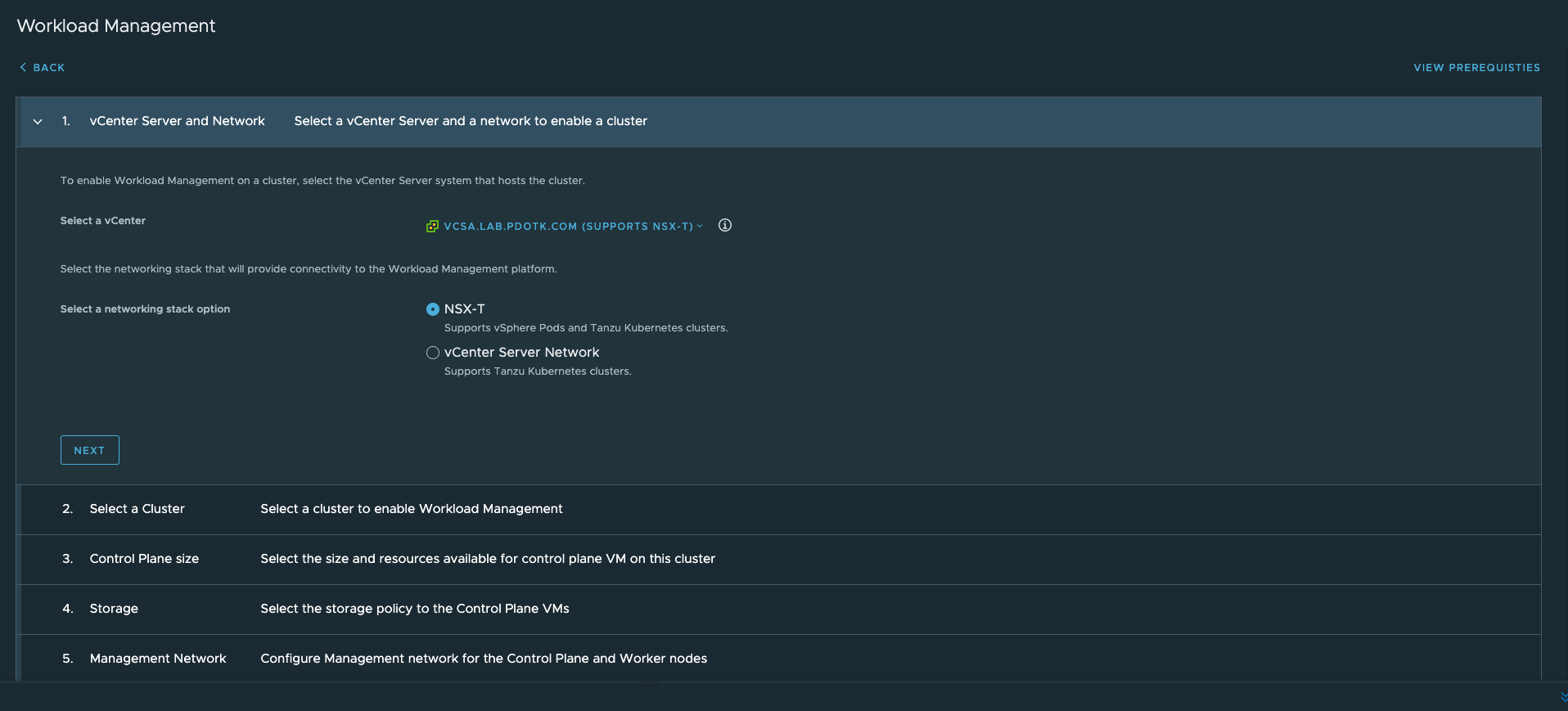
Attempt 1: NSX-T 3.1 not supported
My first attempt at turning on WCP ended real quick as I got the error that NSX 3.1 was not supported. In hindsight, this was obvious because I had an “older” version of vCenter (7.0GA). I was at peak frustration and started to doubt myself for choosing the latest version of NSX-T…but I not giving up yet.
note to self - do not choose the latest version for your lab #homelab
— PK (@pkblah) January 29, 2021
My options were to either rollback NSX or to upgrade vCenter to the latest version that would support NSX-T 3.1. Needless to say, I was done with NSX Configuration having done it 3 times already!
Detour: Upgrade Hosts to U1
vCenter upgrade pre-check showed that I needed to upgrade 6.7 hosts to 6.7U1 and 7.0 hosts to 7.0U1. I was able to easily upgrade my Compute Cluster hosts (Dell R730) from 7.0 to 7.0U1 through the lifecycle manager. There were no VM workload on this cluster yet and that helped speed things up. As I was going to upgrade my Management hosts to 6.7U1, I wanted to see if I could sneak in a 7.0 ESXi upgrade (by bypassing the CPU check). This unfortunately didn’t work on the Dell R620 as my storage devices were not getting picked up due to a change introduced in ESXi 7.0 (Deprecation of VMKLinux). I decided to once again leave my management hosts at 6.7 U1 which I was able to upgrade manually.
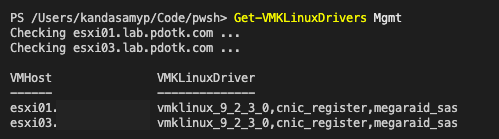
Referenced Links
- https://rufus.ie/ - helps create bootable USB drives from ISO
- https://www.virtuallyghetto.com/2020/03/homelab-considerations-for-vsphere-7.html
- https://blogs.vmware.com/vsphere/2019/04/what-is-the-impact-of-the-vmklinux-driver-stack-deprecation.html
Detour: Upgrade vCenter to 7.0U1
With my hosts upgraded to the version required for vCenter 7.0 U1, I got busy with my first vCenter upgrade and to go along with the theme of this post, I ran into some issues with the GUI based upgrade. The upgrade through the Admin GUI would just hang at 0% for hours and (like a dummy) because the GUI estimated the finish time to 240 minutes i ended up waiting 4 hours (not once but TWO times!). After some research I ended up downloading the patch ISO and upgrading from CLI which ended up working like a charm!
Alright! Now with vCenter upgraded to 7.0 U1, we should no longer see NSX issues.. Fingers crossed, let’s turn on WCP! As I proceed to turn it on, I had a major facepalm moment when I see that NSX-T is not longer required to enable Workload Management with the October Update for vCenter!
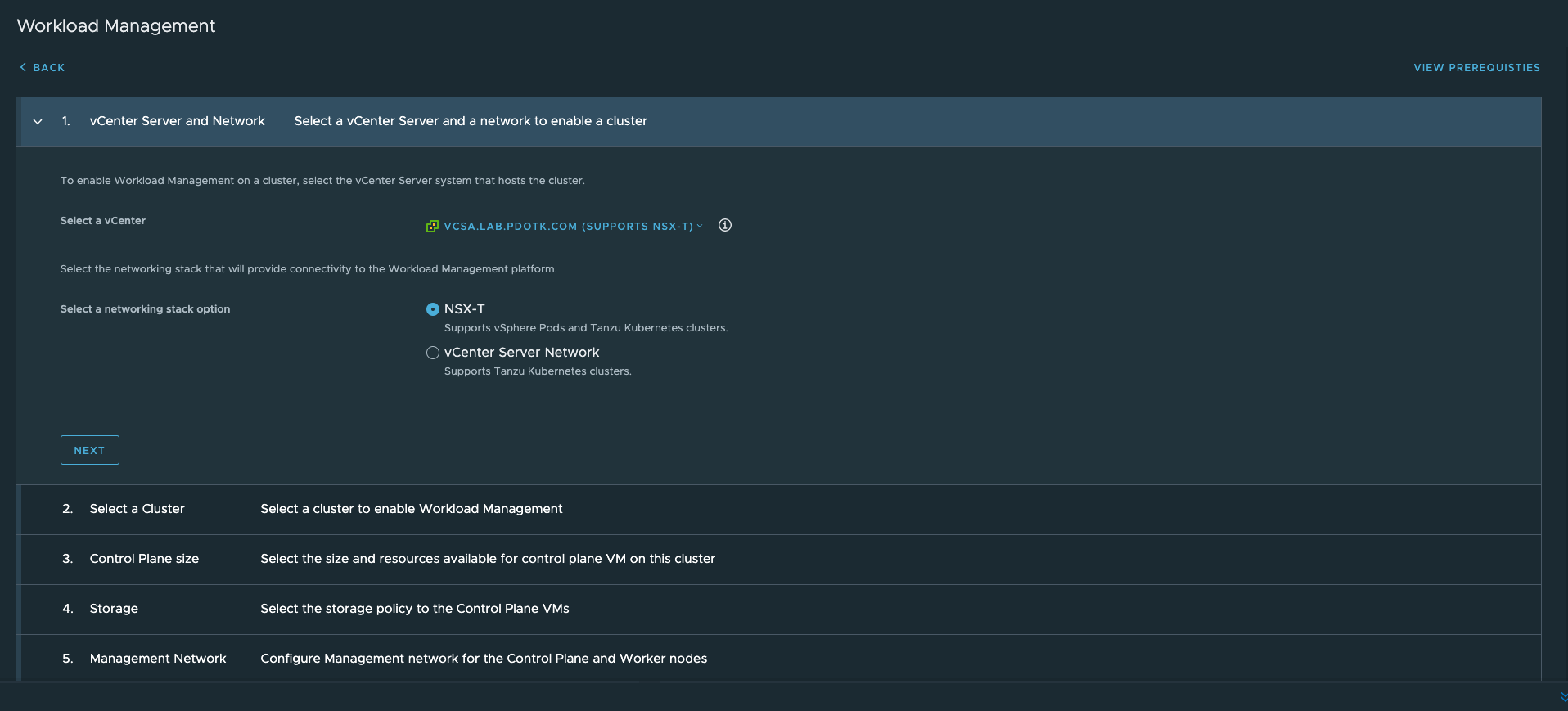
Referenced Links
Attempt #2: Errors, More Errors
I soldier on with enabling WCP with NSX-T since they provided additional features and I did learn a bunch going through the NSX-T setup! After enabling WCP I get an Error: Error configuring cluster NIC on master VM. This operation is part of API server configuration and will be retried. I couldn’t find any good lead on solving this at the time. The error seemed to indicate that the API server was not reachable but I wasn’t able to figure out why since the API server IP were on the same subnet as my Management IPs (which I was able to ping).
NSX Manager on the other hand has alarms that indicated that the NSX Container Plugin (NSXP) was having issues

I go through the pre-requisites again and now see that the minimum 3 nodes for the Supervisor VM cluster. I tried to get smart by adding a nested ESXi appliance to my cluster until Kalyan Krishnaswamy sent me this article about a 2 node deployment where I see copious references to William Lam’s Follow blog reminding me that there is always an easier way!
Referenced Links
- https://www.jamesmcleod.xyz/2020/11/06/tanzu-deployment-error/
- https://davidstamen.com/2020/04/10/part-4-deploying-vsphere-with-kubernetes-enabling-vsphere-with-kubernetes/
- https://www.viktorious.nl/2020/05/07/vsphere-7-with-kubernetes-2-node-lab-deployment/
- https://www.virtuallyghetto.com/2020/04/deploying-a-minimal-vsphere-with-kubernetes-environment.html
- https://community.pivotal.io/s/article/pks-1-4-cluster-creation-failure-ncp-node-agent-fails?language=en_US
Attempt #3: Cross Check
I am now back to my 2 node vSAN setup w/ Witness and configured the /etc/vmware/wcp/wcpsvc.yaml in VCenter to have just 2 Supervisor Control Plane VM. This time even before I turn on WCP, I go through every aspect of my setup and cross checking my setup against all the other setup instructions that I could find!
As I go through the very detailed Pivotal Docs, I notice that I overlooked a few things which I promptly addressed
- I had a NSX Management cluster (2 manager nodes) and I didn’t setup the certificate with the VIP information
- I had not setup my switch/router with static routes to the egress and ingress n/w range from the Management VLAN
I had also downloaded the logs from my previous WCP attempts and started to analyse them. I googled every error and eventually found this community post for the Security Context is missing error which indicated something about having consistent MTUs. While the error I observed in the logs didn’t have anything to do with MTU, the theory made sense! Reminding me how bad networking setup can screw everything up! As I go through all my vmkernel and switch settings in vCenter I noticed that I had my physical switch MTUs setup at 1900 (for NSX-T) and left most of the things in vCenter set at the default 1500.
After having consistent MTUs and fixing the other items described above, I tried enabling WCP.. fingers crossed, bracing for more errors!
and to my surprise…
Referenced Links
- https://docs.pivotal.io/tkgi/1-9/nsxt-3-0-install.html#nsxt30-mgmt-ssl
- https://communities.vmware.com/t5/VMware-vSphere-Discussions/vsphere-7-with-kubenetes-alway-authorized-fail/m-p/2295879
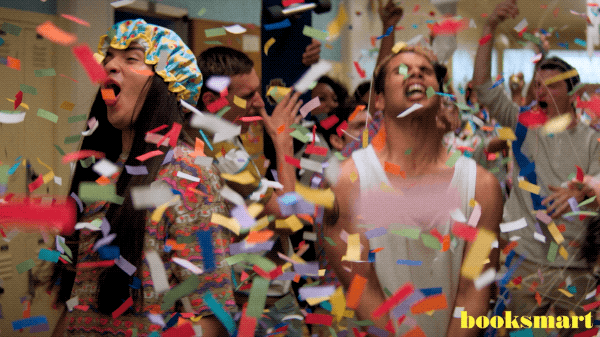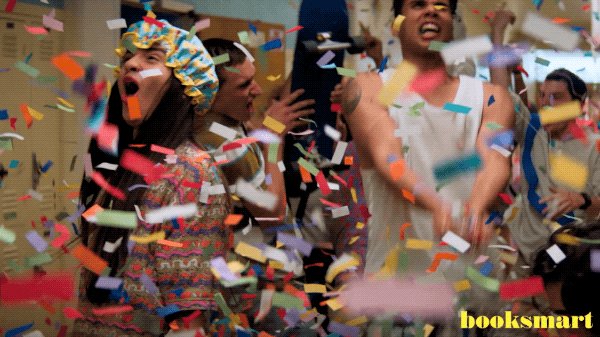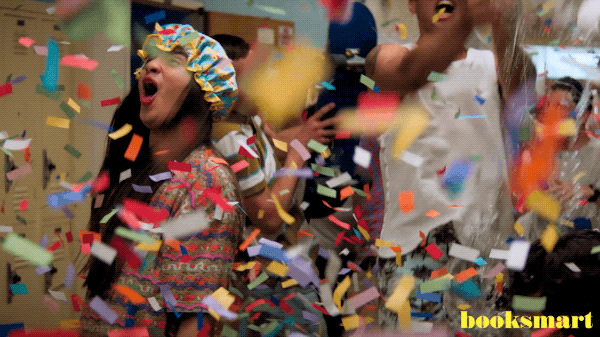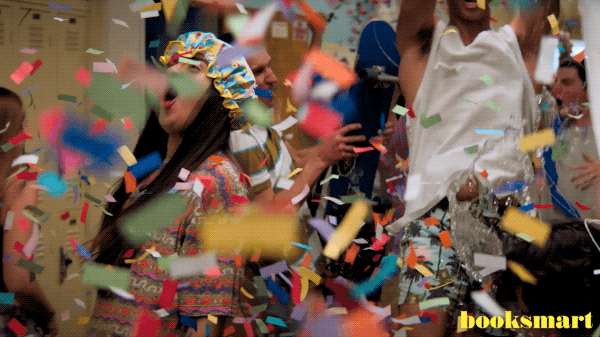
Workload Management is a game changer as it enables you to manage Containers and VMs within the same platform! For those that are just looking to work with Kubernetes and wondering if you need to go through this rather elaborate setup to get started, the answer is NO! There are several easy methods
- Just K8s: Leverage the Cloud Platforms (Amazon EKS, GKE, K8s on Azure) to easily spin up a cluster.
- Automated vSphere 7 with K8s: Use William Lam’s automated method to spin up this entire setup or
- Just K8s (but manually): You could also manually provision your cluster by using my Bootstrapping Kubernetes on Ubuntu 20.04 using kubeadm w/ Calico post
Thanks to the help of the community and their blogs, I was able to quickly pick up where I left off and get to this monumental moment where I have vSphere enabled with Kubernetes! Thanks again to the #vExpert community for all the invisible helping hands! 😄
I’ve tried to reference all the posts that I could recall and if there are any that I’ve missed that you think could be relevant here, please comment and I’ll be happy amend!
While this may have been a trivial setup for some, I had to go through a steep learning curve. Hopefully this post serves as a good guide on what to avoid and look out for as you get started with Workload Management on vSphere! I want to sign off by encouraging everyone to gravitate towards learning new ideas, technologies and concepts! Dive headfirst into embracing new experiences however uncomfortable or difficult as they are and I’m positive it will not go to waste! 🤘